


Data Mesh, Data Fabric, and DataOps: what should you choose for your modern data platform?
This article explores modern data management approaches—Data Mesh, Data Fabric, and DataOps—highlighting their principles, benefits, and considerations for choosing the right data platform.

In today’s data-driven world, businesses need agility, flexibility, and scalability—qualities that conventional data architectures often struggle to provide. This is where modern data management philosophies like Data Mesh, Data Fabric, and DataOps come into play, each offering their approach to solve various data management challenges. But how do you know which one(s) to choose? Let’s explore these concepts, their principles, and their strengths and weaknesses to help you make the best choices for your organization.
Why we need a modern data platform
Traditional data warehouse struggles to keep up with the diverse and voluminous data generated today:
Unstructured data, which is a huge missed opportunity in many cases since a majority of data is not tabular/structured.
Streaming and near real-time data
Support for AI & machine learning, which is an increasingly important use case and not well supported by traditional data warehouses
Ever increasing amounts of data, which needs new storage solutions and a more decoupled architecture
Potential organizational bottlenecks and scalability problems because of centralization
Support for data sharing and standards
This is the reason we have seen new technical data architectures such as Data Lakes and more recently Data Lakehouses. However, the challenges are not only technical. Data management is a "sociotechnical" topic and includes challenges around organization and people, methods and processes as well. That's why the solution is not only a new technical platform, but you need a more holistic approach.
Data Mesh: principles and concept
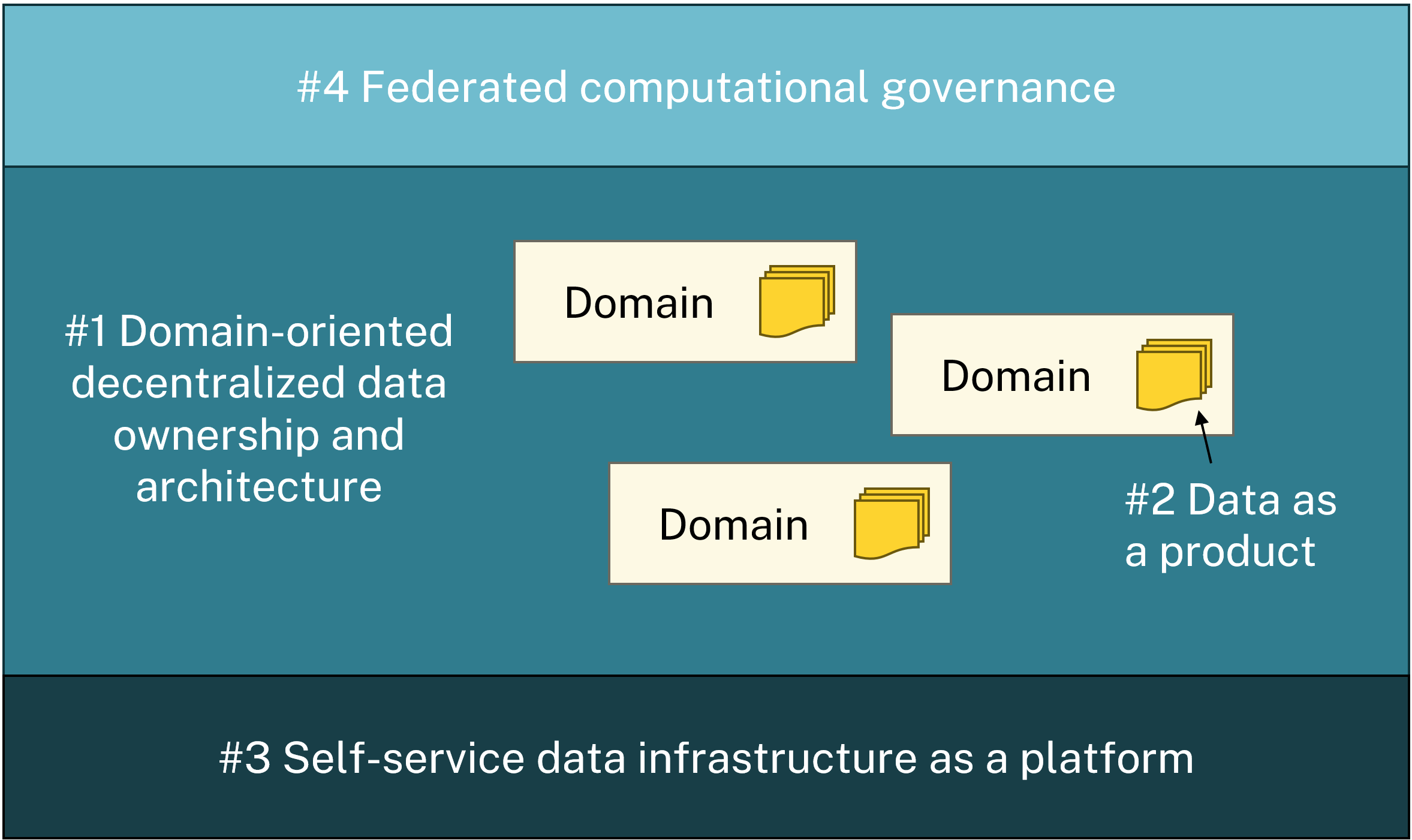
Data Mesh, coined by Zhamak Dehghani in 2019, is a paradigm that challenges the centralized nature of traditional data management. It introduces a distributed organization, where data ownership is spread across teams based on their domain expertise. Data Mesh is driven by four core principles:
Domain-oriented decentralized data ownership and architecture: Data is managed by decentralized teams. The teams are domain-oriented (e.g., marketing, sales, finance) and each team takes responsibility for its own data, maintaining autonomy over its usage and management. This principle stands in contrast to having a centralized team that could become a bottleneck.
Data as a Product: Data teams treat data as actual products, focusing on product management, usability, discoverability, and value delivery for end-users. Each data product is autonomous and serves a specific purpose.
Self-Service Data Infrastructure: A self-service platform allows teams to provision data infrastructure without the need for deep technical expertise, promoting agility. It is also much more efficient to have a common type of infrastructure than having each domain-oriented team setting up their infrastructure completely independently.
Federated Governance: Governance is shared between the domain-oriented teams and a central team, ensuring consistency while maintaining flexibility within each domain. The central team oversees policies and standards for data security and regulations, while the domain-oriented teams can set context specific rules for their domain.
Data Mesh is only a concept, not a fully-fledged architecture. Domain teams still need data warehouses, data lakes, data lakehouses, or similar solutions to store and manage their data. While Data Mesh offers a new way of thinking about data ownership and governance, decentralization adds complexity and makes governance more difficult. As a result, relatively few true Data Mesh implementations currently exist.
Data Fabric: Integrating and connecting data

Unlike Data Mesh, the concept of Data Fabric lacks a universally accepted definition, but it is for example summarized by Gartner as "an integrated layer of connected data." Data Fabric aims to unify disparate data sources by weaving them into a comprehensive and interconnected platform, with the goal of simplifying data access and improving productivity. In theory, a Data Fabric is for "Any data source to any target (any type, any size). Batch and real-time."
Characteristics of Data Fabric:
Orchestration: Orchestration tools are used to manage, coordinate, and automate data workflows across different systems and platforms, ensuring seamless integration and movement of data.
Augmented Data Catalog: Data catalogs help discover and manage data assets in the organization, like a directory. An "augmented" data catalog uses AI to support data organization and tagging.
Active Metadata: Metadata is what connects the various parts of the Data Fabric together. Opinions differ on what "active metadata" really is, but consider it a dynamic, continuously updated layer of information that captures the context, lineage and relationships of data, adapting to changes.
Recommendation Engines: These engines use insights from active metadata and user behaviors to offer suggestions, making data more useful and accessible.
Knowledge Graph: A knowledge graph helps link different pieces of data and provides context, making it easier to derive meaningful insights across various domains.
Data Preparation and Delivery: Tools for data preparation and delivery (ETL/ELT tools) help ensure that data is properly cleaned, transformed, and made available in the right format, streamlining the process of making data ready for analysis or consumption.
Data Fabric is also a concept rather than an architecture. It acts as a connective tissue across the organization, making data accessible and valuable irrespective of its origin. This approach enhances agility and allows businesses to tap into their data assets quickly, which is vital for organizations that need a holistic data view without restructuring their entire data ecosystem. However, much of the data fabric is still immature technology and as a result relatively few Data Fabrics currently exist.
DataOps: Blending Agile, DevOps, and Lean for Data Management
DataOps is an agile approach to managing and delivering data, inspired by the principles of DevOps, Agile, and Lean. Its goal is to streamline the end-to-end flow of data across the organization, from collection to transformation to delivery, and enable continuous data delivery with minimal errors. In essence it means "Building, testing, and deploying data platforms, the same way we do software platforms."
The DataOps Manifesto outlines the philosophy of DataOps, emphasizing continuous integration and delivery (CI/CD), collaboration, and automated testing. It promotes adaptability, empowering teams to respond to changing requirements quickly and deliver data insights with greater speed and reliability.
DataOps has borrowed the idea of Statistical Process Control from Lean. It's about creating quality metrics and following up on them to increase operational excellency. Examples of significant metrics are data quality, loading times and error rates.
"Data Products instead of data projects" is also a way of working that is associated with DataOps. The idea is the same as in Data Mesh, treating data as autonomous and purposeful products, focusing on product management, usability, discoverability, and value delivery for end-users. A project usually has a short time-span, while a data product can remain and be maintained for a long time.
Pros and Cons of DataOps
Pros:
Faster delivery: Continuous integration and automation speed up the data pipeline.
High data quality: Automated testing reduces errors and enhances data integrity.
Cross-functional collaboration: DataOps fosters communication between different teams, improving alignment with business goals.
Cons:
Requires cultural change: Moving to DataOps often involves changing traditional mindsets and practices.
Complexity: Implementing DataOps can be technically and organizationally challenging and may require advanced skills.
Upfront investment: Automation tools and practices require an initial investment in time and resources.
Picking the best choice(s) for your organization
Ultimately, there is no “one-size-fits-all” solution. The right choice depends on your organization’s data needs, culture, infrastructure, and goals. Consider your business requirements, data management capabilities, and readiness for cultural change.
If your central organization is a bottleneck and you need decentralization, look into Data Mesh.
If you need to unify multiple data solutions and are ready to invest heavily in your metadata, look into Data Fabric.
If you are into agile, processes and automation, look into DataOps.
Each of these philosophies—Data Mesh, Data Fabric, and DataOps—targets different needs and in practice they complement each other and can be combined. Also you don’t need to fully accept them - you can adapt them and take the parts you find most useful for your use case.
Whatever you choose, be ready that there is no easy “out of the box” path to any of these options. You will have to invest very significant time to make them work.
Note! The content on this blog reflects my personal opinions and does not represent my employer. As the publisher, I am not responsible for the comments section. Each commenter is responsible for their own posts.